Gate Ventures研究洞察:Parallel Execution突破瓶颈,以太坊EVM的性能挑战与并行执行之路
分享到朋友或朋友圈
以太坊的 EVM 由于其单线程架构,面临着严重的性能问题,尤其是在处理高并发交易时。这种串行执行方式限制了网络的吞吐量,导致处理速度远远不能满足日益增长的用户需求。我们通过一步一步分析 EVM 串行执行的全流程,发现了以太坊想要实现并行执行的两个主要软件问题: 1. 状态识别 2. 数据架构以及 IPOS 消耗,针对这两个问题,各家都有自己的解决方案,面临多个权衡包括 EVM 兼容与否、识别使用乐观还是悲观并行、数据库的数据架构、更多的使用内存高效率还是硬盘的高并发通道、开发者开发体验、硬件的要求、模块化还是单片链架构,这些都值得去仔细权衡。
我们同时也注意到了,虽然并行执行像是指数级拓展了区块链,但是其仍然有瓶颈,这个瓶颈是分布式系统天生的,包括P2P网络、数据库本身吞吐量等问题。区块链计算想要达到传统计算机的计算能力,仍然有很长的路要走。目前并行执行本身也面临一些问题,包括并行执行的硬件要求越来越高,节点越来越专业化带来的中心化、审查风险,并且在机制设计上依赖于内存、中心集群或者节点也会带来宕机风险,与此同时,在并行区块链间跨链通信也会是一个问题。这仍然值得更多团队去探索。
从各家的架构以及对 EVM 的兼容的思考中,我们深知,颠覆性创新来自于对过去的不妥协。区块链技术仍然在早期,而性能提升也远未到达终局,我们迫不及待的想要见到更多不愿意妥协、不循规蹈矩的创业者构建更加强大且有趣的产品。
Ethereum EVM 一直以来在性能上都饱受诟病,主要是由于其落后的架构设计,其中不支持并行化的问题是最为严重的。对于交易并行化,相当于一条马路变成了多道跑道,这能为道路上的可容纳流量带来指数级的提升。
深入 Ethereum,在当前执行层与共识层分离的背景下,我们会发现 EVM 的交易处理全部是串行执行。
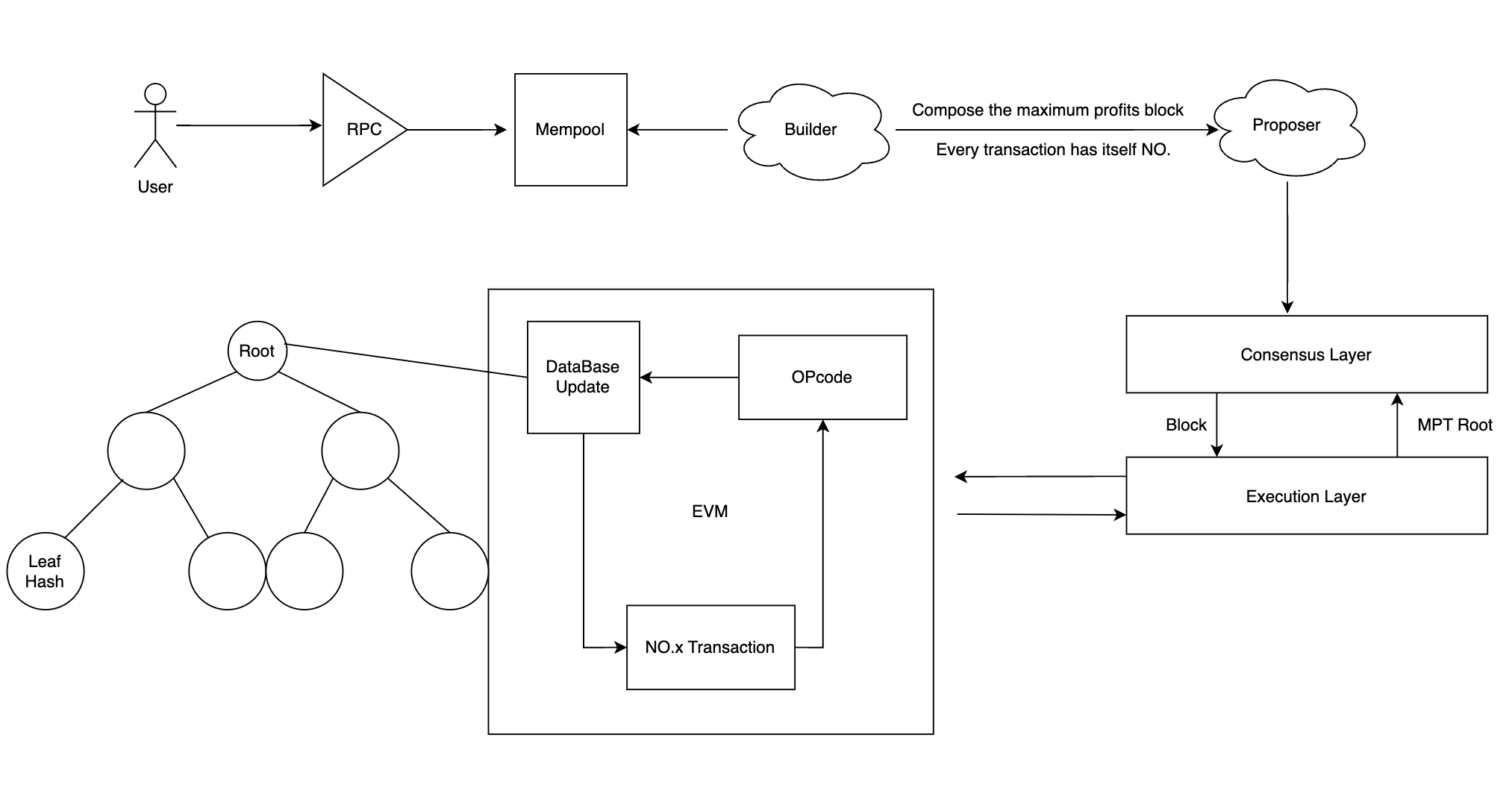
以太坊的交易执行流程
在以太坊的交易中,用户首先会将交易通过 RPC 发送到 Mempool,之后 Builder 选择利润最大化的交易,并且将其排序,此时交易的顺序已经确定。Proposer 将交易广播给共识层,共识层确定该区块的有效性,比如是来自有效的发送着,区块中的交易作为执行负载发送给执行层,执行层执行交易,执行交易的简略过程如下:(以 Alice 发送 1 ETH 给 Bob 为例)
1. 在执行节点的 EVM 中,其会把 NO.0 的交易指令转换为 EVM 能够识别的 OPcode 代码。
2. 然后根据 OPcode 硬编码,确定这笔交易需要的 Gas。
3. 执行的交易过程中,需要访问数据库得到 Alice 和 Bob 余额的状态,然后执行交易 opcode 知道 Alice 余额减一,Bob 加一,向数据库写入/更新这一余额状态。
4. 从区块中,取出 NO.1 的交易继续顺序的循环执行,直到该区块的交易执行完毕。
5. 数据库中的数据主要是以 Merkel 数的形式来存储的,最终该区块的交易全部顺序执行完毕以后,数据库中的状态根(存储账户状态)、交易根(存储交易的顺序)、收据根(存储交易的附带信息,如成功状态和 Gas Fees)会提交到共识层。
6. 共识层收到状态根即可非常轻便的证明交易的真实性,执行层将验证数据传回共识层,区块现在被视为已验证。
7. 共识层将区块添加到其自己的区块链的头部并对其进行证明,并通过网络广播该证明。
这个就是整个全流程,里面涉及到了区块内交易的顺序执行,主要是每一笔交易都有自己的 NO,并且每一笔交易都可能需要读取数据库中的状态,并且重写状态。如果不是顺序执行,那么就会导致状态冲突,因为有一些交易是相互依赖状态的。所以,这也是为什么 MEV 选择串行执行的原因。
MEV 的简单,这同时也意味着,带来了串行执行带来了极低的性能表现,这是导致以太坊仅仅两位数 TPS 的主要原因之一。在现在的聚焦消费者应用程序的发展背景下,EVM 作为落后的设计范式,面临着亟待改善的性能问题,虽然当前 EVM 已经走向了一个完全以 Layer 2 为中心的路线图,但是其 EVM 的问题,如 MPT trie 结构,数据库如 LevelDB 的低效等都是亟待解决的。
伴随着这一问题的演进,有许多项目开始着手构建并行高性能 EVM,以此来解决以太坊老旧的设计范式。通过在 EVM 的流程中,能够看出这里有两个高性能 EVM 主要解决的问题:
1. 交易状态分离:交易由于存在状态的相互依赖,因此需要串行运行,需要将状态独立的交易分离出来,然后想依赖的仍然需要顺序执行。那么就可以分发给多个核心并行处理。
2. 数据库架构改进:以太坊使用 MPT 树,由于一笔交易涉及大量的读取操作,通常情况下,这会导致极高的数据库的读写操作,也就是 IOPS(IO Per Second)要求极高,通常的消费级 SSD 无法满足这一需求。
总的来说,目前的主流的区块链构建方案中,往往在软件上的优化主要是交易状态的分离以构建可并行的交易以及数据库的优化以支持高并发的交易状态读取。伴随着对高性能的需求,大多数项目的对硬件的需求也在提高。以太坊一直以来对于 Layer 1 的性能拓展都非常谨慎,因为这意味着中心化与不稳定性。但是当前的高性能 EVM 往往抛弃了这些给自己添加的桎梏,引入了极致的软件改进、P2P网络优化、数据库重构、企业级专业硬件。
Github
通常数据库中的数据都会以一种抽象的方式组织在一起,以太坊就是以 MPT 树的方式。MPT 树最后的数据状态会形成一个根节点,如果任何的数据有了更改,根节点都会变化,因此使用 MPT 能够很便捷的验证数据完整性。
我们举一个例子来感受一下当前数据库的资源消耗情况:
在一个拥有 n 个叶子节点的 k 叉 Merkle Patricia Tree(MPT)中,更新单个键值对需要进行 O( klog k n ) 次读取操作和 O( log k n ) 次写入操作。比如,对于一个拥有 160 亿个键(即 1 TB 区块链状态)的二叉 MPT,这相当于大约 68 次读取操作和 34 次写入操作。假设我们的区块链想要处理每秒 10, 000 笔转账交易,需要更新状态树中的三个 key-value,一共需要 10 , 000 x 3 x 68 = 2 , 040 , 000 次,也就是 2 M IOPS(I/O Per Second)操作(在实践中,可以通过压缩和缓存减小一个数量级,大约是 20 万 IOPS,我们不做展开)。目前主要的消费级 SSD 完全无法支持这一操作(Intel Optane DC P 580 0X 800 GB 仅仅为 10 万 IOPS)。
MPT 树当前面临了许多问题,包括:
● 性能问题:MPT 由于其层次化的树结构,在更新数据时,往往需要遍历多个节点。每次状态更新(如转账或智能合约执行)需要进行大量的哈希计算,并且由于需要访问许多层的节点,性能较低。
● 状态膨胀:随着时间推移,区块链上的智能合约、账户余额等状态数据会不断增加,导致 MPT 树的大小持续膨胀。这会导致节点需要存储越来越多的数据,给存储空间和同步节点带来了挑战。
Etherscan
● 无法高效处理部分更新:当树结构中的某个叶子节点发生变化时,整个路径上的节点都会受到影响。以太坊 MPT 需要重新计算从叶节点到根节点的所有哈希值,这导致即便是局部的状态变更,也需要对大量的节点进行更新,从而影响性能。
我们能够看到,当前 MPT 下的以太坊面临多种问题,其也提出了多种解决方案,比如针对状态膨胀会进行状态修剪、针对 MPT 性能问题会构建新的 Verkel Tree。通过构建新的 Verkel Tree 结构的数据库,通过减小树的深度来减少部分更新时数据库的访问次数,使用向量承诺(主要以 KZG 承诺为主)来减小证明的体积同时也减少数据库的访问量。
总之,过去的 MPT 树的涉及以及过于老旧,面临了许多新的挑战,因此改变数据的存储方式如使用 Verkel tree 已经被列入其路线图。但是这仅仅是非常微弱的修改,仍然并没有涉及到并行执行以及高并发下要求的高 IOPS 的解决方案。
新公链标配并行执行
就如我们上一部分所言,并行执行意味着从单车道改为多车道,在多车道的十字路口往往需要一个中间件如红绿灯协调,发送信息以使各个车道能够顺畅通过。区块链也是,在并行交易中,我们需要把用户的交易通过一个状态识别的中间件,让状态互不相干的交易能够分离从而达到并行执行,并行执行带来的高 TPS,同时意味着对底层数据库的大量 IOPS 需求。几乎所有的新 Layer 1 有以并行执行作为标配 feature。
对并行执行的实现方案有多种分类方式,按照底层的虚拟机,分为 EVM(Sei、MegaETH、Monad)和 None-EVM(Solana、Aptos、Sui)。按照交易状态的分离方式,可以分为乐观执行(假设全部交易都不想干,如果状态冲突则回退这部分交易重新执行)和提前声明(开发者需要在程序中声明访问的状态数据)。这些分类也同时意味着权衡。
接下来,我们将不以是否为 EVM 作为划分,而是单纯的从各个公链在状态分离以及数据库方面的改善情况来进行比较。
MegaETH
MegaETH 严格来说是一个以性能为主要目标的异构区块链,其依赖于以太坊的安全性使用 EigenDA 作为共识层和 DA 层。而其作为执行层,将最大程度的释放硬件性能提升 TPS。
对于交易处理的优化手段其分为三种:
1. 状态分离:采用交易优先级的方式的流式区块构建。这一模式和 Solana 的 POS 有相似之处,实际上 Solana 的交易也是流式构建的,但是 Solana 没有优先级,全部靠速度来竞争。而 MegaETH 希望能够为交易构建某种优先级算法。
2. 数据库:针对 MPT Trie 的问题,其构建了新的数据结构来提供更高的 IOPS。我们查阅 MegaETH 的代码库时,发现其也有在同时参考 Verkel Trie 的设计方式。
3. 硬件专业化:通过将排序器中心化和专业化,实现内存计算从而显著提高 IO 的效率。
实际上,MegaETH 希望作为 Layer 2 将安全性和抗审查性委托给 Ethereum,这样就能够最大限度的优化节点,通过 POS 的经济安全性来保障排序器的不作恶,这里有许多值得 chanllenge 的点,但是我们不做展开。虽然 MegaETH 在构建并行执行的交易,但是实际上,其目前并未实现并行执行,其希望将单一排序器节点的性能做到极限以此最大程度的以硬件拓展性能,然后再通过并行执行拓展性能。
与 MegaETH 不同,Monad 是一条单独的链,其符合我们介绍的并行执行需要优化的两个重要的点,并行执行的状态分离以及数据库重构。我们简述 Monad 使用的具体方法:
● 乐观并行执行:对于交易的识别,采用了最为经典的默认所有交易的状态都是不想关的,当遇到状态冲突时,再重新运行交易,这一方式目前在 Aptos 的 Block-STM 机制上运行良好。
● 数据库重构:Monad 为了提高数据库的 IOPS,因此重构了兼容 EVM 的数据结构 MPT(Merkel Patricia Tree),Monad 实现了兼容 Patricia Tree 的数据结构,并且支持最新的数据库的异步 I/O,能够支持在读取某个状态时,不需要等待对该数据的写结束。
● 异步执行:在以太坊上,虽然我们严格的识别了具体的共识层以及执行层,但是我们发现共识层与执行层(与 Layer 2 作为执行层的概念不相同,在这里指以太坊仍然需要执行节点以执行以太坊上的交易)仍然是耦合在一起的,执行将执行后更新的 Merkel Root 给到共识,这样共识层才能投票以达成共识。Monad 认为状态在排序完成的那一刻就已经定下来了,所以只需要对排序后的交易达成共识,甚至不需要执行来揭示这一结果。这一想法,让 Monad 能够巧妙的将共识层与执行层拆离开来,以此来实现共识同时执行。节点可以在保持对 N 区块的共识投票的同时,去执行 N-1 区块的交易。
当然,Monad 还有许多其它的技术包括新的共识算法 MonadBFT 等共同构建了一个高性能的并行 EVM Layer 1 。
Aptos
Aptos 从 Facebook 的 Diem 团队拆分而来,其与 Sui 共同视为 Move 双雄,虽然如此,两家因为技术理念的不一致,导致了当前两家的 Move 语言已经大不相同,整体来说,Aptos 更遵循当初 Diem 的设计,而 Sui 对该设计进行了大刀阔斧的修改。
针对并行执行需要解决的问题:
● 状态识别:乐观并行执行,Aptos 开发了 Block-STM 并行执行引擎,默认乐观执行交易,如果遇到状态冲突,则重新执行。目前这一技术已经被普遍接受,如 Polygon、Monad、Sei、StarkNet 均使用这一技术。
● IO 改进:Block-STM 使用了多版本的数据结构以避免状态冲突。举个例子,假设我们其他人正在写一个数据库,那么正常来说,我们是无法访问的,因为需要避免数据的冲突,但是多版本的数据结构可以允许我们访问过去的版本。问题在于,这个方案会造成巨大的资源消耗,因为你需要为每个线程生成一个可见的版本。
● 异步执行:和 Monad 类似,交易传播、交易排序、交易执行、状态存储和区块验证都是同时进行的。
当前 Block-STM 已经被大多数公链接受,并且被 Monad 称为多亏了这一技术的出现,能够有效减缓开发者的压力,但是 Aptos 面临的问题是,Block-STM 的智能化带来了对节点要求过高的问题,这一问题需要专业化硬件以及中心化的去解决。
Sui
Sui 也和 Aptos 一样,继承自 Diem 项目。相比之下,Sui 使用悲观并行化,严格验证交易之间的状态依赖关系,并采用锁定机制来防止执行期间发生冲突。而 Aptos 希望能够减轻开发者的开发负担。
● 状态识别:与 Aptosb 不同,采用了悲观并行化,因此开发者需要声明自己的状态访问,而不是将并行的状态识别交给系统来处理,增加了开发者的开发负担,减轻了系统的设计复杂度,同时也增加了并行化的能力。
● IO 改进:IO 改进目前主要是改进模型,以太坊使用基于账户的模型,每个账户维护其数据,但是 Sui 采用了 Objects 的结构代替账户模型,该架构的改进会显著影响并行性实施的难度与峰值性能。
Sui 因为不存在 EVM 的历史遗留问,也没有兼容性的问题,其基于 Move 系都进行大刀阔斧的更改,对于账户模型,其也提出了创新性的想法 Objects,这种抽象层面上的创新实际上更难。但是其 Objects 模型带来了对并行处理的诸多好处,也是因为 Objects 模型,其构建了一个非常与众不同的网络架构,在理论上确实能够无限拓展。
Solana - FireDancer
Solana 被视为并行计算的先驱,Solana 的理念一直以来都是区块链系统应该随着硬件的进步而进步,以下是当前 Solana 的并行处理方式:
● 状态识别:与 SUI 一样,Solana 也使用确定性并行方式,这来自于 Anatoly 过去处理嵌入式系统的经验,在嵌入式系统中,通常会预先声明所有状态。这使 CPU 能够知道所有的依赖关系,从而使它能够预先载入内存的必要部分。结果就是优化了系统执行,但是再一次,它要求开发人员预先做好额外的工作。在 Solana 上,程序的所有内存依赖都是必需的,并在构建的交易(即访问列表)中进行声明,从而使运行时(runtime)能够高效地调度及并行执行多个交易。
● 数据库:Solana 利用 Cloudbreak 构建了自己的自定义帐户数据库,其使用的是以账户为模型,帐户数据分布在多个“分片”上,类似于将图书馆分为几层,并且其可以根据需要增加或者减少层数以负载均衡。其在 SSD 上会映射给内存,因此通过流水线设计可以快速通过内存操作 SSD,同时支持多数据的并行访问,能够同时并行处理 32 个 IO 操作。
Solana 通过确定性并行方式要求开发者声明其需要访问的状态,这确实与传统的变成情况相似,在程序构建方面是需要开发者自己构建并行应用程序,而程序调度和运行时流水线异步并行则是项目需要构建的。在数据库方面,其通过自建自己的 DataBase 进行数据并行化以提高 IPOS。
于此同时,后续的 Solana 迭代的客户端,Firedancer 是由 Jump Trading 这一具有非常强大工程能力的量化巨头所推动研发的,与 Solana 的愿景相同,目标是消除软件效率低下并将性能推向硬件的极限。其改进主要是针对硬件底层的改进,包括P2P传播、硬件的 SIMD 数据并行处理等,这与 MegaETH 的想法非常相似。
Sei
● SeiDB:整个数据库解决方案是基于 Cosmos 的 ADR-065 提案基础上构建的,其实体使用的是 PebbleDB ,数据结构的设计上将数据分为活动数据和历史数据,SSD 硬盘内的数据映射成内存上的数据,同时 SSD 数据使用 MemIAVL 树结构,而内存数据使用 IAVL 树( Cronos 发明)进行状态承诺,就是其提供运行共识的状态根。MemIAVL 的抽象思想是,每次提交新块时,我们都将从该块的交易中提取所有更改集,然后将这些更改应用于当前内存中的 IAVL 树,从而为最新块生成树的新版本,以便我们可以获得块提交的 Merkle 根哈希。因此,相当于使用内存进行热更新,这能让大部分的状态访问都位于内存上,而不是 SSD,以此来提升 IOPS。
SeiDB 的主要问题是,如果最新的活跃数据存放在内存上,那么会出现宕机数据丢失的情况,所以 MemIAVL 引入了 WAL 文件和树快照。在一定的时间内,需要快照内存上的数据,存放在本地的硬盘上,控制一定的时间快照间隔,及时控制数据膨胀对内存的 OOM 影响。
方案对比
对于数据结构,我们看到一个比较有趣的一点,Monad 尽量放在 SSD,但是硬盘的读取速度远低于 Memory 内存,但是价格便宜很多。Monad 放在 SSD 考虑了价格、硬件门槛以及并行程度,因为现在 SSD 能够支持 32 通路的 I/O 操作,以此提升更多的并行能力。相反,Solana、Sei 却选择内存映射,因为内存的速度远高于 SSD。一个是横向拓展并行通路,一个是纵向拓展降低 I/O 消耗。这也是出现了 Monad 的节点要求是 32 GB,但是 Sei 和 Solana 需要更多内存的原因。
除此之外,以太坊的数据结构是由 Patrci Tree 演进得到 Merkel Patric Tree 得来,所以 EVM 兼容的公链需要兼容 Merkel Trie,因此其无法构建像 Aptos、Sui、Solana 等抽象方式去思考资产,以太坊是以账户模型,但是 Sui 是 Objects 模型、Solana 是数据与代码分离的账户模型,而以太坊确实耦合在一起的。
颠覆性创新来自于对过去的不妥协,在商业的角度确实也需要考虑开发者群体以及过去的兼容性,对 EVM 的兼容有其利弊。
展望
当前并行执行的主要优化组件都有了比较清晰的目标,主要集中在如何识别状态、如何提高数据的读取和存储的速度,因为这些数据的存储方式会导致读取或者存储一个数据造成额外的开销与消耗,特别是 Merkel trie 引入了根验证这一有点,但是带来了超级高额的 IO 开销。
虽然并行执行,像是指数级拓展了区块链,但是其仍然有瓶颈,这个瓶颈是分布式系统天生的,包括P2P网络、数据库、等问题。区块链计算想要达到传统计算机的计算能力,仍然有很长的路要走。目前并行执行本身也面临一些问题,包括并行执行的硬件要求越来越高,节点越来越专业化带来的中心化、审查风险,并且在机制设计上依赖于内存、中心集群或者节点也会带来宕机风险,与此同时,在并行区块链间跨链通信也会是一个问题。
虽然,目前并行执行仍然有一定问题,各家都在探索最佳的工程实践,包括以 MegaETH 为首的模块化设计架构和 Monad 为首的单片链设计架构。目前并行执行的优化方案,确实证明了区块链技术正在不断的朝着传统的计算机优化方案靠近,并且越来越底层进行优化,特别是数据存储、硬件、流水线等技术上的细致优化。但是,这句仍然存在瓶颈和问题,因此仍然有非常广阔的探索空间留给创业者。
颠覆性创新来自于对过去的不妥协,我们迫不及待的想要见到更多不愿意妥协的创业者构建更加强大且有趣的产品。
免责声明:
以上内容仅供参考,不应被视为任何建议。在进行投资前,请务必寻求专业建议。
Gate Ventures 是 Gate.io 旗下的风险投资部门,专注于对去中心化基础设施、生态系统和应用程序的投资,这些技术将在 Web 3.0 时代重塑世界。Gate Ventures 与全球行业领袖合作,赋能那些拥有创新思维和能力的团队和初创公司,重新定义社会和金融的交互模式。
官网:https://ventures.gate.io/Twitter:https://x.com/gate_venturesMedium:https://medium.com/gate_ventures
